Intermittent SMTP Connection failures
Postmortem
Note: This outage did not affect our inbound email filtering service, nor any of our API services except for the Cloudflare Workers sending API.
Executive Summary
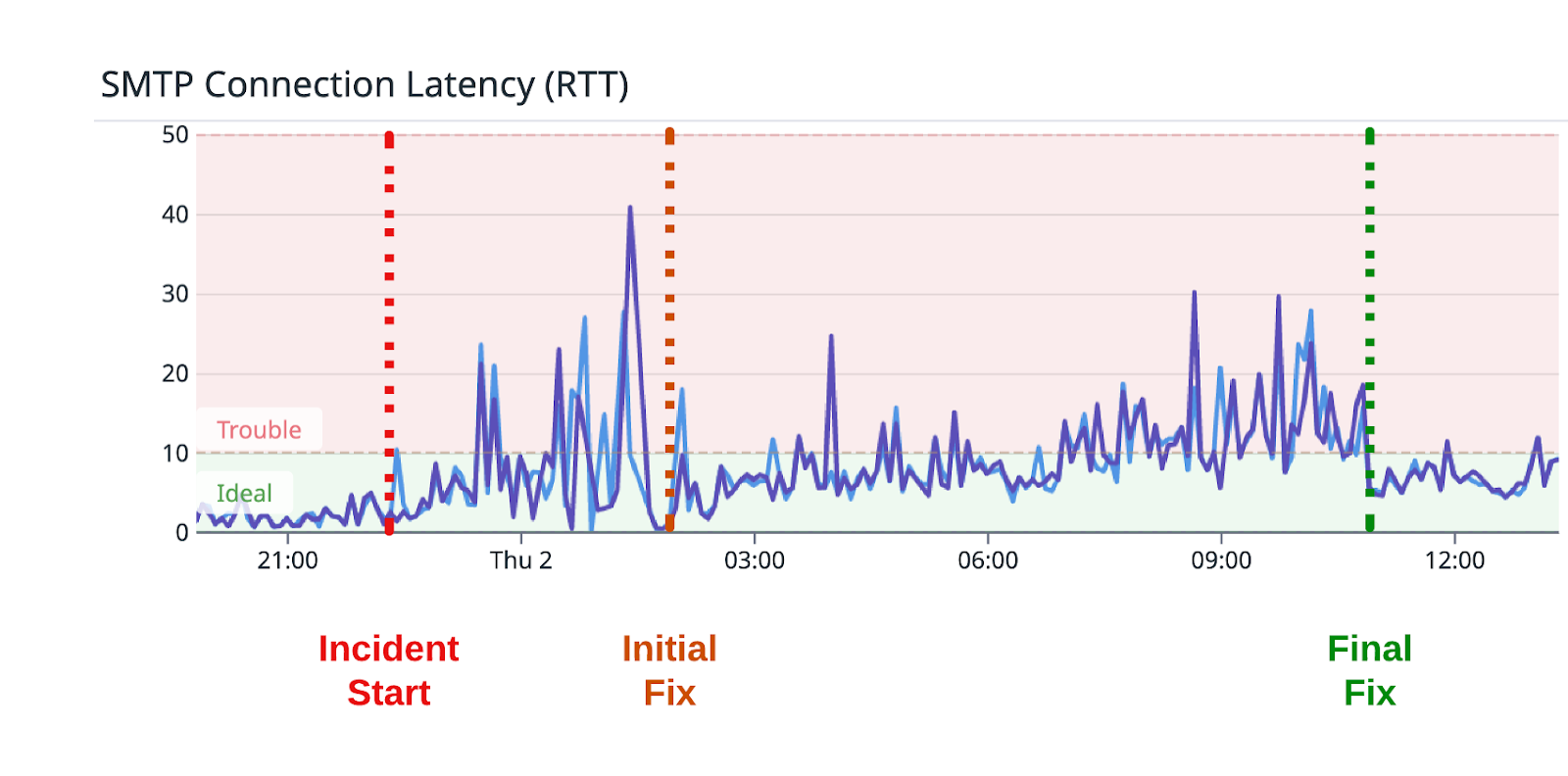
At 07:32 UTC on March 2nd, 2023, MailChannels Outbound Filtering experienced a service outage. After an initial remediation at 10:44 UTC, work continued until a final fix was in place at 18:50 UTC. During this outage, email delivery was heavily delayed.
Incident Timeline
On March 2nd 07:32 UTC, our monitoring system alerted us of elevated round-trip delivery times in our outbound email delivery service. Our 24x7 operations team immediately began investigating the issue and escalated the issue to senior engineers at 07:51 UTC after initial steps at remediation failed. An incident was created on our status page (status.mailchannels.net) at 08:01 UTC. At 08:09 UTC, after initial efforts to restore service failed, we paged the rest of our operations engineering team. By 08:15 UTC, team members began flowing into our Slack channel to work on the problem.
Initial investigations by our senior engineers uncovered a resource exhaustion issue. Unfortunately, increasing various resource limits and bringing on board additional CPU and memory resources did not resolve the issue. The issue persisted across both of our logically independent clusters, so attempts to resolve the problem by shifting traffic to one cluster or the other did not resolve the issue.
At 10:44 UTC, we deployed changes to our configuration that seemed to stabilize the service. The status page was updated to reflect this change, which we believed would restore service within an hour or so.
At 13:20 UTC, after receiving continued complaints from customers, the team was brought back to continue working on the problem. At 15:27 UTC, we finally found the root cause of the issue and began working on a definitive resolution. At 18:50 UTC, a policy was deployed to prevent abuse of the service by the imposition of new adaptive message size limits.
Monitoring and Response Timeline
The chart below shows the average number of seconds it takes to submit a message to the MailChannels Outbound service; usually, this figure is less than one second. This metric is one of two key metrics we monitor to get a sense of whether the service is operating correctly. Any time the connection latency exceeds five seconds, we consider that a major outage is occurring.

Root Cause Analysis
The MailChannels Outbound service provides outstanding reliability, achieving delivery of email messages within our target parameters the vast majority of the time. Over the past 11 years, we have built extensive monitoring systems to predict when an outage might be about to occur so that we can get ahead of the issue before it becomes a global problem. These monitors detect many issues that our customers never see, because the problem is resolved long before causing an outage.
Outages occur because of an unforeseen situation a) for which we don’t yet have predictive monitoring, or b) for which our systems have no coping mechanism. In the present case, the outage occurred for both of these reasons.
The root cause of today’s issue was a flood of very large messages from a handful of senders. To give you a sense of the magnitude of this flood, the chart below illustrates how the volume of large messages handled by our service spiked to nearly 14-times their median baseline.
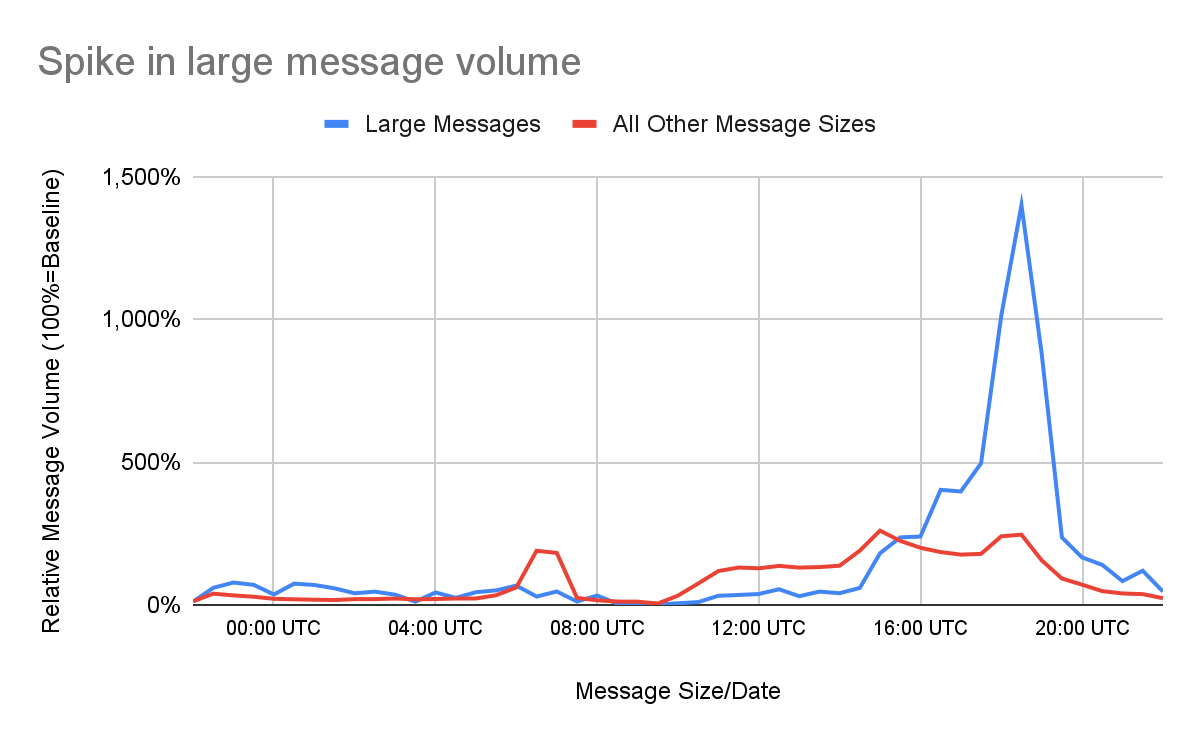
Why a spike in large message volume is a significant problem
Large email messages present a particular problem because they take up a large amount of disk space in our queues while they are being delivered to downstreams; large messages also occupy a great deal of memory within other parts of the infrastructure during processing. As shown in the chart below, data processed within our queues spiked to 300% of normal during the incident as the queues worked to process the flood of very large messages.
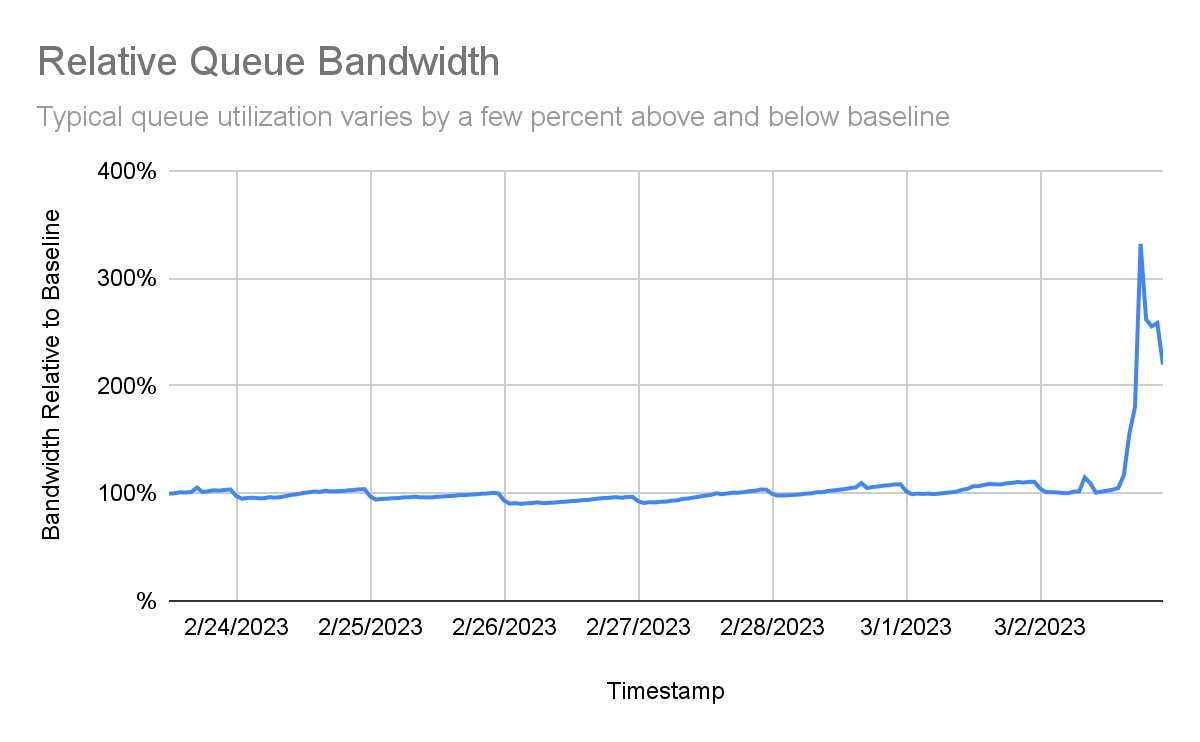
Remediation
Immediate Remediation
To fix this issue, we wrote a new message handling policy that prohibits individual senders from delivering an exceptional number of large messages in a short period of time. Writing this fix took about 15 minutes using our flexible JavaScript-based policy system. The new policy is adaptive, applying limits across a variety of timescales so that short-term breaches of the data limit result in only a brief impact on the sender. We estimate that only 0.002% of senders (one in 50,000) will ever be rate limited by this new policy. The new rate limit generates a distinctive SMTP error that contains a URL pointing the sender at information to help resolve the problem.
Long Term Remediation
In addition to the immediate remediation described above, we are also writing code to automatically scale queue capacity more aggressively should a similar situation ever occur again. Our baseline queue capacity has already been increased; however, we will also ensure that our services can autoscale queue storage as needed.